
PM2.5の予測
時系列データの予測を行う。例に用いるのは北京のPM2.5の量だ。ここから入手できる。
UCI Machine Learning Repository: Beijing PM2.5 Data Data Set
データ属性は以下の通り。
No: row number
year: year of data in this row
month: month of data in this row
day: day of data in this row
hour: hour of data in this row
pm2.5: PM2.5 concentration (ug/m^3) (これを予測する)
DEWP: Dew Point (℃)
TEMP: Temperature (℃)
PRES: Pressure (hPa)
cbwd: Combined wind direction
Iws: Cumulated wind speed (m/s)
Is: Cumulated hours of snow
Ir: Cumulated hours of rain 最初に使うのはFaceBook製の軽量予測パッケージProphetだ。WindowsだとPyStanのインストールに苦しむらしいが、Google Colabだとpipで一発だ。
!pip install fbprophet
%matplotlib inline
import pandas as pd
import numpy as np日本語の他のブログで見かける例だと、公式HPに置いてある加工済みのデータセットを用いている場合が多いが、ここではデータの加工方法も紹介する。まずはNaNを含んだ行を消して、pm2.5の値があまりにばらついているので、対数を取っておく。つまり、MSE (mean square error) でなくMSPE (mean square percent error) を評価尺度にする。
prsa = pd.read_csv("PRSA.csv")
prsa.dropna(inplace=True)
prsa["pmlog"] = np.log(prsa["pm2.5"]+0.001)次に、バラバラの列に保管されている日時データを合わせて日付時刻の列を作る。また、Prophetではデータフレームのds(datestamp)列をX、y列をyにする必要があるので、そのように名前を変えておく。
prsa["datetime"] = prsa.year.astype(str) + "-" + prsa.month.astype(str) + "-"+prsa.day.astype(str)+" "+prsa.hour.astype(str)+":00:00"
prsa["datetime"] = pd.to_datetime(prsa.datetime)
df_input = prsa.reset_index().rename(columns={'datetime':'ds', 'pmlog':'y'})最後の2000データを検証データとし、それ以外のデータで訓練する。書き方のフレームワークはscikit-learnと同じだ。
from fbprophet import Prophet
model = Prophet(growth='linear', daily_seasonality=True)
model.add_seasonality(name='monthly', period=30.5, fourier_order=5)
model.fit(df_input[:-2000])予測を行う際には、1時間を1単位になるように指定する必要があるので,引数のfreqを’H’ (Hour) にしておく。
future = model.make_future_dataframe(periods=2000, freq='H')
forecast = model.predict(future)
model.plot(forecast)
plt.show()予測はyhat属性に保管されているので、MSEを計算する。
((forecast.yhat[-2000:] - df_input["y"][-2000:])**2).mean()
>>>
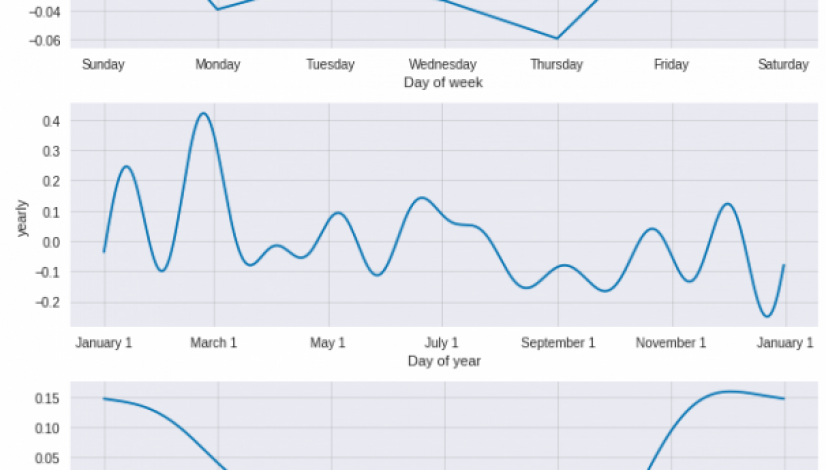
1.627238182728774季節変動については月次を追加したが、そのほかトレンド、週、年、日などのコンポーネントに分解して図示できる。これが冒頭に示した図になる。
model.plot_components(forecast)
plt.show()元データには、色々な列の情報が含まれている。それらを用いてscikit-learnのRandom森で予測してみる。カテゴリー変数も含まれているので、ダミー列に変換しておく。
prsa2 = pd.get_dummies(prsa, drop_first=True)
訓練データと検証データを適当に作って、ランダム森で訓練する。
from sklearn.ensemble import RandomForestRegressor #ランダム森
forest = RandomForestRegressor()
forest.fit(X_train, y_train) # 学習
yhat = forest.predict(X_test) # 予測
from sklearn import metrics
metrics.mean_squared_error(y_test, yhat)
>>> 0.6570177322490524MSEはだいぶ改善される。
最後に、埋め込み層を用いた深層学習で予測を行う。用いるのはfastaiだ。
prsa.drop("pm2.5", axis=1, inplace=True)
procs = [FillMissing, Categorify, Normalize] #前処理の種類を準備.
valid_idx = range(len(prsa)-2000, len(prsa)) #検証用データのインデックスを準備.
dep_var = 'pmlog' #従属変数名とカテゴリー変数が格納されている列リストを準備.
# DataBunchのインスタンスdataを生成.
data = TabularDataBunch.from_df(".", prsa, dep_var, valid_idx=valid_idx, procs=procs,
cat_names=["year", "month", "day", "hour", "DEWP", "cbwd","Is","Ir"])年と月と日と時刻はカテゴリーデータにして埋め込み層を自動生成して予測を行う。このデータ束を用いて、学習器を作成する。
learn = tabular_learner(data, layers=[1000,500],ps=[0.001,0.01], emb_drop=0.4, metrics=mean_squared_error)1サイクル法によって、訓練を行う。過剰適合しないように、重み減衰パラメータをやや大きめに設定しておく。
learn.fit_one_cycle(2, 1e-2, wd=0.4)
>>>
epoch train_loss valid_loss mean_squared_error time
0 0.596473 0.864749 0.864749 00:09
1 0.547652 0.673393 0.673393 00:09
2 0.536905 0.610631 0.610631 00:092エポックで0.61程度が出るようだ。
ふと思ったのだが、検証時における属性風向とかは分かっていないので、これはずるい。手法を適用するだけではなく、理論が大事というわけだ。実際には,天気予報を先に知って,その情報をもとにPM2.5の量を予測することになるだろう.たとえば,前日の天気予報から翌日のPM2.5の量を知ることができれば,マスクを付けていくべきかどうかが判断できる.